Im Magazin „ Microcomputing" wurde im April 1981 der folgende Artikel abgedruckt.
Ich habe den Artikel hier übersetzt
|
Die Assemblerquelle für das im Text angegebene Listing findet sich auch auf der SIG/M1 Ausgabe 75.
[Hier das Original 8080-Programm
und hier als Z80-Quelle angepasst für den M80 Assembler].
Irgendwo in den Weiten des Use-Net habe ich eine ähnliche Implementiereung der Shell-Metzner Sortierung gefunden.
[hier als 8080-Assembler Programm
und hier als Z80-Assembler Programm].
Auch auf der SIG/M Ausgabe 78 findet sich ein weiteres Beispiel.
|
|
Ein interessanter Artikel zum Thema Sortierung.
|
|
No list of records is too short or long for this assembly-language Shell-Metzner sort.
Sorta Super Fast
By Albert J. Marino
This program will let you sort 32K in one minute.
This means you can sort 2000 names in one minute and, in fact, can sort 10,000 names in a reasonable time.
The routine can easily be used with any BASIC or other language as long as it supports external (user) routines and has a POKE or similar function.
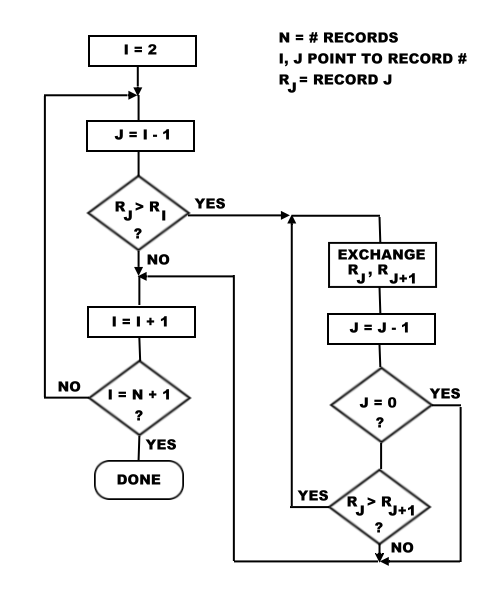
I originally wrote a machine language program that worked on the algorithm shown in Fig. 1.
|
Fig. 1.
|
This routine was short and simple, required no scratch space and was about four times faster than a modified bubble sort.
I have never seen this algorithm implemented by anyone else and it might be unique; it certainly is good enough for most applications.
However, when the files reached 2000 names, I found that this routine was taking two to three minutes.
Since the time for the routine is approximately a function of N2, this meant that 10,000 names would take over an hour.
I decided I needed a better routine.
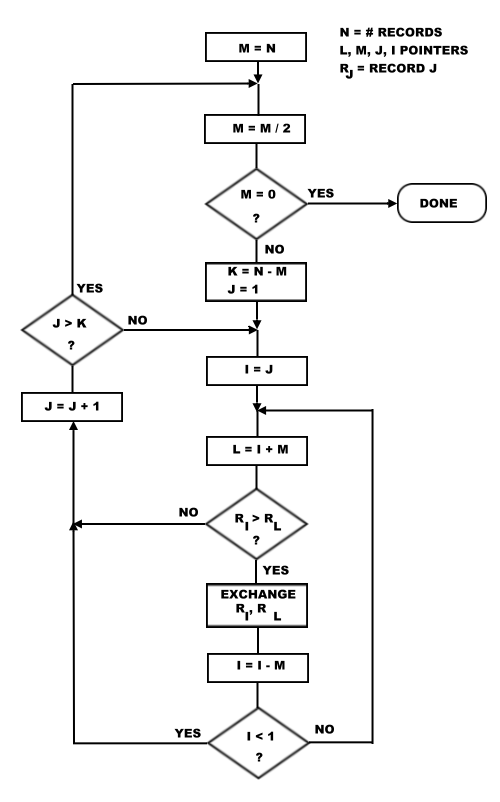
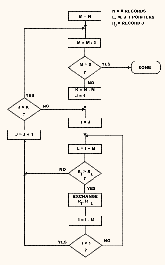
The one I settled on was the Shell-Metzner sort shown in Fig. 2.
|
Fig. 2.
|
Listing 1 shows the 8080 assembly-language program for this sort.
Of course, the program will work for any 8080- or Z-80-based computer.
The listing happens to be assembled at location
AB00H but can be reassembled for any starting address.
Note that the routine takes 203 bytes, including the 16-byte scratch area at the beginning.
Using the Routine
Once the program is in memory, it can be used by any other program, as long as it is not overwritten.
To use it follow these steps:
Put the records to be sorted into memory starting at any location and sequentially up in memory.
The records must be the same length.
Put the number of records to be sorted in location n1 (AB00H in our listing) and also in location m1 (AB02H).
Note that the numbers are 16-bit (two-byte) numbers and are stored in standard reversed format with low byte first and high byte second.
For example, if the number of records is 4000 (=0FA0H) then 160 (A0) is put into location AB00H and 15 (0F) is put into location AB01H.
In like manner, put the length of each record into location k1 (AB04,5) and the starting address in location j1 (AB06,7).
Transfer control to the program (call) at location ORG + 16 (AB10H).
The program will then sort the records in ascending order and return.
To sort in descending order, change the byte at location ORG + 6FH (AB6FH) from D2 to DA before calling the program.
Test Results
To give times for comparison, I filled my memory with a random pattern of 0s and 1s.
This minimum number of values for each location results in the maximum times for sorting.
Test results are shown in Table 1a.
The results for some of the same tests using the original algorithm are shown in Table 1b.
| AMOUNT OF |
# |
# |
TIME TO SORT |
| MEMORY |
RECORDS |
BYTES/REC |
SECONDS |
| 16K |
4K |
4 |
22 |
| 16K |
2K |
8 |
22 |
| 16K |
1K |
16 |
15 |
| 32K |
8K |
4 |
65 |
| 32K |
4K |
8 |
75 |
| 32K |
2K |
16 |
54 |
| 32K |
1K |
32 |
34 |
| Table 1a. |
| 16K |
4K |
4 |
775 |
| 16K |
2K |
8 |
285 |
| 16K |
1K |
16 |
110 |
| Table 1b. |
|
The improvement is significant especially for large numbers since the new algorithm time is approximately a function of N log(N).
An Example
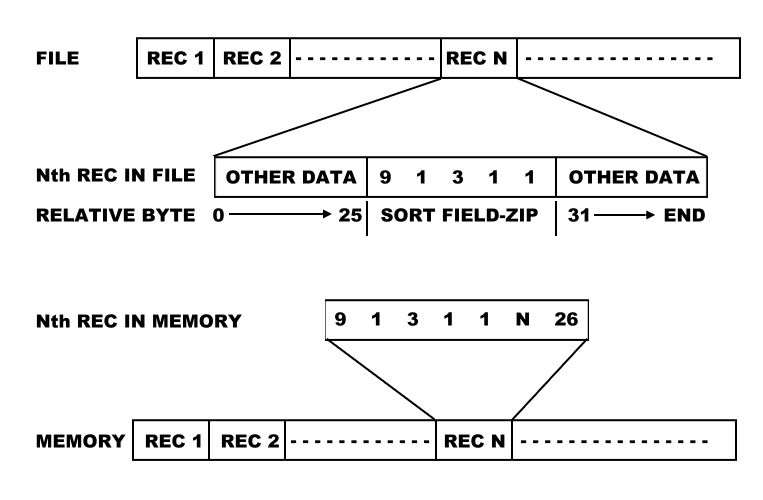
In general, a good technique to use is:
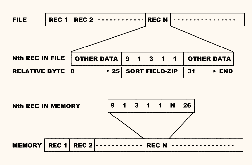
For each record, load the field to be sorted into memory with a pointer.
Fig. 3 shows a typical example.
Sort using the routine given here.
Use the now sorted pointers to access each record, in order.
|
Fig. 3.
|
As an example, suppose you want to do an alphabetical sort of names stored in a file in ASCII format
(this is the normal string and file format of most languages).
Getting the correct results is not difficult, but it does require some care.
Consider the following correctly sorted names:
de la Fleur, Conrad
Diebold, Tom
DiGeorge, Olaf
DiGeorgeo, Dick
di Georgeo, Len
Di Georgeo, Pete
Dillingham, Sam
If you had sorted these names by just loading last name first name, into memory, you would have gotten:
Di Georgeo, Pete
DiGeorge, Olaf
DiGeorgeo, Dick
Diebold, Tom
Dillingham, Sam
de la Fleur, Conrad
di Georgeo, Len
To get around this problem, make the following changes as the names are loaded into memory for sorting:
Convert all characters to lowercase (or uppercase).
Remove all spaces and punctuation in the last name.
Insert a delimiter between last name and first name with ASCII value lower than letters
(I used a comma).
Truncate this string plus the pointer to 16 bytes or pad with blanks if shorter.
For example, de la Fleur, Conrad, becomes "delafleur,conxx" and Jones, Sam, becomes "jones,sam00000xx," where xx is the pointer and the 0's are blanks.
This allows 14 letters to sort on.
With over 6000 names, I have not had a mistake caused by this length restriction;
with less names you might get by with even less.
After you've done the above and sorted using this routine, you can use the now-sorted pointers to access the original records in alphabetical order.
Large Files
If the file is too large to be loaded into memory, even using the above method of loading only the sort field then you need an additional technique.
One method, if you don't know anything about the distribution of the field you're sorting on, is:
Read into memory as above, stopping when you have filled memory.
Sort this block 1 and save on disk.
Read more fields in, sort and save as block 2, 3, etc.
Merge the blocks by reading each block item by item and saving the appropriate entry on disk in a separate file.
This works since each block is individually sorted.
This method works for files of any size, even ones that span multiple disks.
Conclusion
The sorting routine given here should let you sort your files on any field within a reasonable time.
For those who wish, this program is available on a CP/M eight-inch disk or TRS-80 five-inch disk for $15 from Compleat Systems, 9551 Casaba Ave., Chatsworth, CA 91311 (213-993-1479).
The disk also contains a Z-80 version that takes 25 percent less space and runs 25 percent faster, and two additional utilities (search and move).
Address correspondence to Albert J. Marino,
Compleat Systems,
9551 Casaba Ave.,
Chatsworth,
CA 91311
| 1. |
Die Gruppe SIG/M (Special Interest Group/Microcomputers), ein Teil des Amateur Computer Clubs aus New Jersey, hatte zur regulären Ausgabe von Public Domain Software diese auf Disketten zusammengestellt.
Die SIG/M Disketten entstanden ab 1980 und die Ausgaben 000 bis 310 sind hier zu finden.
 |
|
Eingescanned von
Werner Cirsovius
August 2002, Ergänzung Dezember 2009
© Microcomputing