|
Im Magazin „Microcomputing" wurde im April 1981 der folgende Artikel (hier in deutscher Übersetzung) abgedruckt.
|
Keine Aufstellung von Datensätzen ist zu kurz oder lang für diese Shell-Metzner-Sortierung in Assembler.
Sortierung Superschnell
Von Albert J. Marino
Dieses Programm erlaubt die Sortierung von 32K in einer Minute.
Das bedeutet, dass 2000 Namen in einer Minute und 10000 Namen tatsächlich in einer angemessenen Zeit sortiert werden können.
Die Routine kann einfach benutzt werden mit BASIC oder einer anderen Sprache, solange diese externe (Benutzer-)Routinen unterstützt und über eine POKE-Funktion oder ähnlichem verfügt.
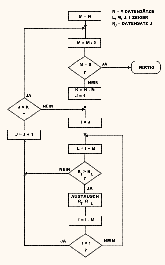
Ich habe ursprünglich ein Maschinenprogramm geschrieben, das nach dem Algorithmus gemäß Abb. 1 arbeitete.

|
Abb. 1.
|
Diese Routine war kurz und einfach, benötigte keinen Arbeitsbereich und war etwa viermal schneller als eine abgewandelte Bubble-Sortierung.
Ich habe diesen Algorithmus nie zuvor von jemanden programmiert gesehen und sie könnte einmalig sein;
sie ist sicherlich gut genug für die meisten Anwendungen.
Als die Daten jedoch eine Größe von 2000 Namen annahmen, stellte ich fest, dass diese Routine zwei bis drei Minuten benötigte.
Da die Zeit der Routine näherungsweise eine Funktion von N2 ist, bedeuten 10000 Namen eine Zeit von über einer Stunde.
Ich beschloss, eine bessere Routine zu schreiben.
Ich entschloss mich für die Shell-Metzner-Sortierung gemäß Abb. 2.
|
Abb. 2.
|
Ausdruck 1
[
Hier als 8080-Assembler Programm
und hier als Z80-Assembler Programm]
stellt das 8080 Assemblerprogramm für diese Sortierung dar.
Natürlich arbeitet dieses Programm für jeden beliebigen Prozessor, der auf der 8080- oder Z80-CPU basiert.
Das Programm wurde für eine Speicherstelle in
AB00H assembliert, es lässt sich aber für jede beliebige Adresse neu assemblieren.
Man beachte, dass die Routine 203 Bytes lang ist, inklusive der 16 Bytes für den Arbeitsspeicher zu Beginn.
Benutzung der Routine
Wenn das Programm in den Speicher geladen ist, dann kann es von jedem anderen Programm benutzt werden, solange es nicht überschrieben wird.
Für die Benutzung sind folgende Schritte erforderlich:
Man legt den zu sortierenden Datensatz ab im Speicher, beginnend an einer beliebigen Speicherstelle in Folge.
Die Datensätze müssen gleich lang sein.
Man speichere die Anzahl der zu sortierenden Datensätze in Speicherstelle n1 (AB00H im Ausdruck) und ebenfalls in Speicherstelle m1 (AB02H).
Man beachte, dass die Zahlen 16-Bit (zwei Bytes) Zahlen sind, die im Standardformat umgekehrt abgelegt werden - zuerst das niederwertige dann das höherwertige Byte.
Ist die Anzahl der Datensätze z.B. 4000 (=0FA0H), dann wird 160 (A0) in Speicherstelle AB00H und 15 (0F) in Speicherstelle AB01H abgelegt.
In ähnlicher Weise speichere man die Länge der Datensätze in Speicherstelle k1 (AB04,5) und die Startadresse in Speicherstelle j1 (AB06,7).
Dann übergebe man die Kontrolle an das Programm (CALL) nach Speicherstelle ORG + 16 (AB10H).
Das Programm beginnt dann mit der Sortierung in aufsteigender Reihenfolge und und kehrt danach zum Aufrufer zurück.
Für eine Sortierung in absteigender Reihenfolge muss das Byte in Speicherstelle ORG + 6FH (AB6FH) von D2 nach DA vor Aufruf des Programms geändert werden.
Testergebnisse
Um Zeiten für einen Vergleich zu erhalten, habe ich den Speicher mit einer Zufallsfolge aus 0 und 1 gefüllt.
Diese minimale Anzahl von Werten für jede Speicherstelle führt zu den maximalen Zeiten bei der Sortierung.
Testergebnisse sind in Tabelle 1a dargestellt.
Die Ergebnisse von einigen derselben Tests mit dem originalen Algorithmus zeigt Tabelle 1b.
| UMFANG DES |
# |
# |
SORTIERZEIT |
| SPEICHERS |
DATENSÄTZE |
BYTES/DATENSATZ |
SEKUNDEN |
| 16K |
4K |
4 |
22 |
| 16K |
2K |
8 |
22 |
| 16K |
1K |
16 |
15 |
| 32K |
8K |
4 |
65 |
| 32K |
4K |
8 |
75 |
| 32K |
2K |
16 |
54 |
| 32K |
1K |
32 |
34 |
| Tabelle 1a. |
| 16K |
4K |
4 |
775 |
| 16K |
2K |
8 |
285 |
| 16K |
1K |
16 |
110 |
| Tabelle 1b. |
|
Die Verbesserung ist bedeutend insbesondere für eine große Anzahl, da der neue Algorithmus annähernd eine Funktion von N log(N) ist.
Ein Beispiel
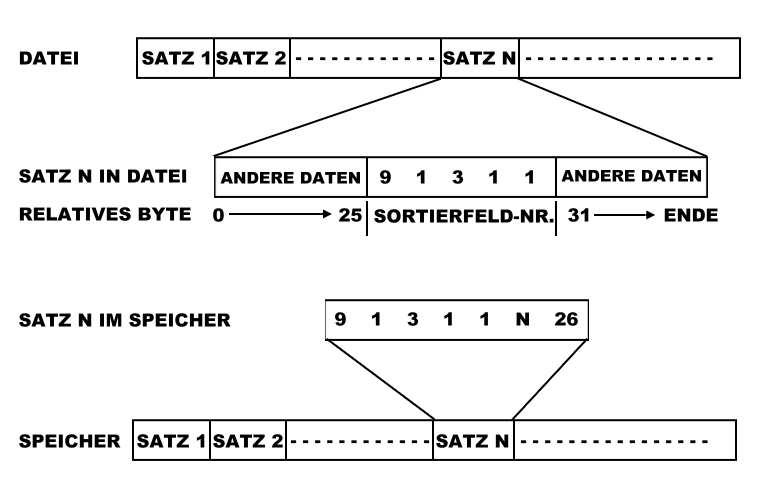
Ein gutes Verfahren für die Nutzung ist im Allgemeinen:
Für jeden Datensatz lade man das zu sortierende Feld in den Speicher mittels eines Zeigers.
Abb. 3 zeigt ein typisches Beispiel.
Man sortiere mit der hier angegebenen Routine.
Man benutze die jetzt sortierten Zeiger, um auf jeden Datensatz nacheinander zuzugreifen.

|
Fig. 3.
|
Als Beispiel wird angenommen, dass eine Sortierung von Namen in alphabetischer Reihenfolge durchgeführt werden soll, die in einer Datei im ASCII-Format abgelegt sind
(dies ist das normale Zeichen- und Dateiformat in den meisten Sprachen).
Das richtige Ergebnis zu erzielen ist nicht schwer, erfordert jedoch etwas Sorgfalt.
Man betrachte die folgenden korrekt sortierten Namen:
de la Fleur, Conrad
Diebold, Tom
DiGeorge, Olaf
DiGeorgeo, Dick
di Georgeo, Len
Di Georgeo, Pete
Dillingham, Sam
Wären diese Namen in den Speicher geladen worden einfach in der Reihenfolge Nachname, Vorname, dann wäre dies das Ergebnis:
Di Georgeo, Pete
DiGeorge, Olaf
DiGeorgeo, Dick
Diebold, Tom
Dillingham, Sam
de la Fleur, Conrad
di Georgeo, Len
Um dieses Problem zu umgehen, sollten folgende Änderungen gemacht werden, wenn die Namen zum Sortieren in den Speicher geladen werden:
Man setze alle Zeichen um in Kleinbuchstaben (oder Großbuchstaben).
Man entferne alle Leerstellen und Zeichensetzung im Nachnamen.
Man füge ein Trennzeichen ein zwischen Nach- und Vornamen mit einem ASCII-Wert, der kleiner ist als ein Buchstabe
(ich habe ein Komma verwendet).
Man begrenze die Zeichenlänge inklusive der Zeiger auf 16 Bytes oder fülle diese mit Leerzeichen auf, wenn sie küzer sind.
So wird z.B. aus de la Fleur, Conrad "delafleur,conxx" und aus Jones, Sam "jones,sam00000xx,", wobei xx den Zeiger und die 0 ein Leerzeichen darstellen.
Dadurch lassen sich 14 Buchstaben für die Sortierung verwenden.
Mit über 6000 Namen hatte ich nie einen Fehler bedingt durch diese Längenbegrenzung; mit weniger Namen kommt man auch mit kürzeren Längen aus.
Nach dem oben Angewandten und der Sortierung mit dieser Routine kann man nun die jetzt sortierten Zeiger benutzen, um auf die originalen Datensätze in alphabetischer Reihenfolge zuzugreifen.
Große Dateien
Falls die Dateiens zu groß für das Laden in den Speicher sind, sogar wenn nur das Sortierfeld nach obiger Methode geladen wird, dann wird eine zusätzliche Technik benötigt.
Eine Methode, falls nichts bekannt ist über die Verteilung des zu sortierenden Feldes, ist:
Einlesen in den Speicher wie oben, beenden, wenn der Speicher voll ist.
Diesen Block 1 sortieren und auf Diskette abspeichern.
Mehr Felder einlesen, sortieren und speichern als Block 2, 3, usw.
Zusammenfassen der Blöcke durch blockweises Einlesen Posten für Posten und abspeichern des entsprechenden Eintrags auf Diskette in eine Extradatei.
Dies funktioniert, da jeder Block einzeln sortiert wurde.
Diese Methode funktioniert für Dateien jeder Größe, sogar für solche, die sich über mehrere Disketten erstrecken.
Schluss
Die hier vorgestellte Sortierroutine lässt Dateien in einem Feld innerhalb einer angemessenen Zeit sortieren.
Für Interessenten steht das Programm auf einer CP/M 8-Zoll Diskette zur Verfügung oder auf einer TRS-80 5-Zoll Diskette zum Preis von $15 von Compleat Systems, 9551 Casaba Ave., Chatsworth, CA 91311 (213-993-1479).
Die Diskette enthält außerdem eine Z-80 Version, die 25 % weniger Platz benötigt und 25 % schneller ist, sowie zwei zusätzliche Routinen (Suchen und Verschieben).
Postanschrift:
Albert J. Marino,
Compleat Systems,
9551 Casaba Ave.,
Chatsworth,
CA 91311
Übersetzt von
Werner Cirsovius
August 2002
© Microcomputing