|
Im Magazin „Microcomputing" wurde im Mai 1980 der folgende Artikel abgedruckt.
Ein Aufsatz zum Thema Hashing mit einem BASIC-Beispiel.
[Ein grundlegender Artikel zu diesem Thema findet sich hier]
|
|
Hashing Revisited
Turn your names into numbers and store and retrieve them with ease.
|
Raymond T. Vizzone
416 Stinson Ave.
Vacaville CA 95688
|
It had been four months since I last argued with my partner
about the merits of hashing.
In fact, I had introduced this technique to him, but was unable to convince him that it
was the best way to store and retrieve data on disk or in arrays.
He didn't like the disadvantages of rehashing—collision, wasted space and overhead.
Neither did I!
I couldn't blame him for ignoring me as he went back to his sorts and binary searches.
I temporarily gave up.
While reading a book called Compiler Construction for Digital Computers by David Gries,
I came across hashing again.
At the same time, I also discovered some similarities existing between how Gries
and Donald Fitchhorn ("DOCUFORM," Kilobaud, August 1978, p. 22) used hashing methods.
With a little more research, l was ready to approach my partner with confidence.
Being subtle, I told my partner that hashing was the only way to retrieve data quickly.
That was an absolute statement.
He ignored me.
I continued, nonetheless, and claimed hashing involves no sorting or binary or sequential searches.
He had heard that song-and-dance before and was still waiting for more explanation.
I emphasized that data is stored in memory sequentially as it is entered, never needing to
be moved.
Data is always available for quick retrieval with no need for rehashing.
That did it!
I had him now.
Implementing HASH-IT
In explaining the hashing method shared by both Gries and Fitchhorn,
I used pictorials and illustrative examples.
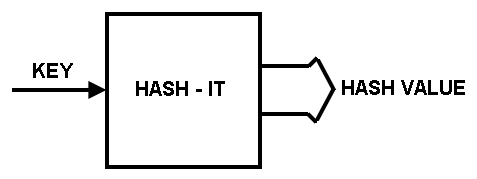
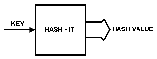
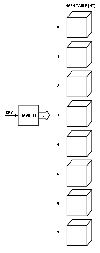
In the beginning, I proposed a function called HASH-IT, which would change names
(KEYS) into numeric values called HASH-VALUES.
The process is shown in
Fig. 1.
The function HASH-IT can be any method of converting an alphanumeric KEY to an integer numeric.
|
Fig. 1. HASH-IT function.
|
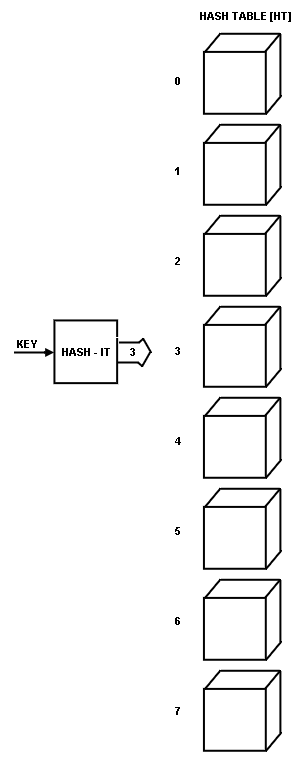
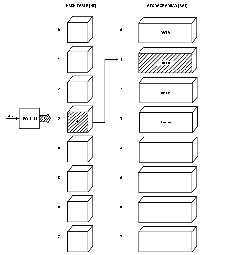
In using HASH-IT, each HASH-VALUE produced points into an array called the HASH TABLE (HT).
For example, a HASH-VALUE of 3 is shown in
Fig. 2.
|
Fig. 2.
|
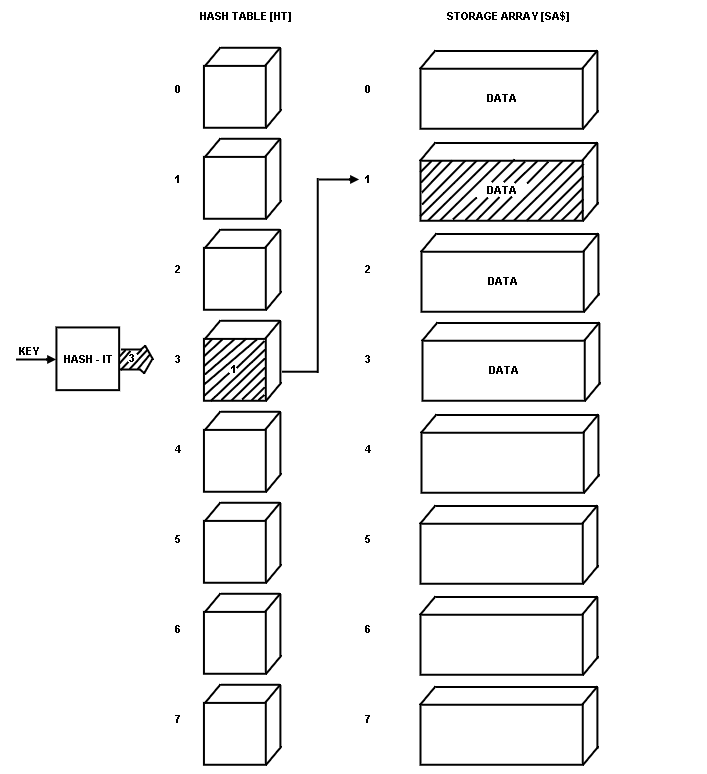
In turn, the contents of each element of the HASH TABLE point to an element of the STORAGE ARRAY (SA$), which holds the data and their respective KEYS (see
Fig. 3).
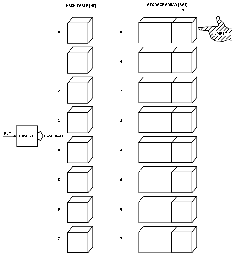
I needed to implement two other concepts to fully explain the madness of this method.
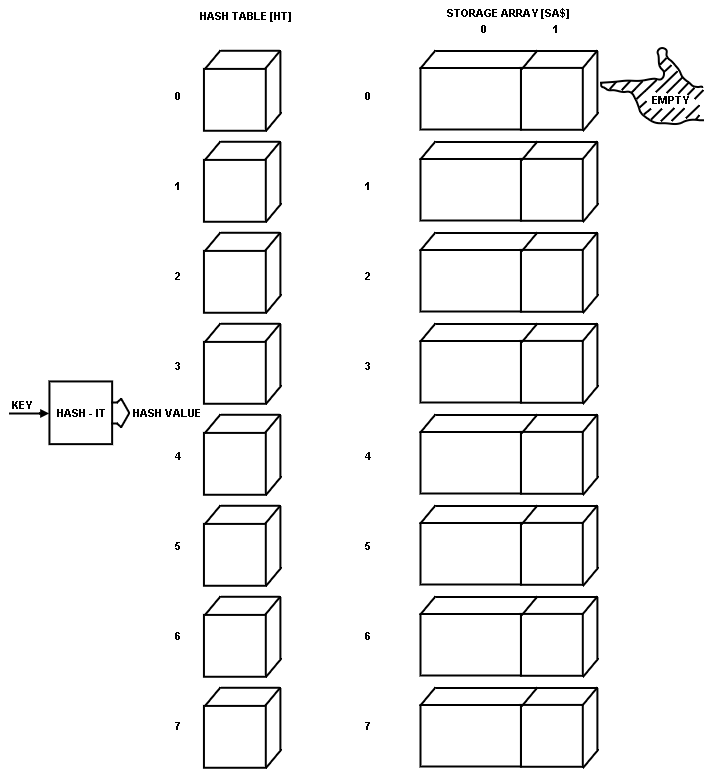
I wanted a pointer to show me where the next empty location of the STORAGE ARRAY was.
For convenience, I called this pointer EMPTY.
I made the STORAGE ARRAY two-dimensional to facilitate a linked-list affair.
The use of this linked list will become clear in later examples.
Fig. 4 shows a general pictorial of everything I needed to explain this hashing method.
|
|
Fig. 3.
|
Fig. 4.
|
To demonstrate this hashing method using
Fig. 4, I used six names to "hash-in" to the STORAGE ARRAY.
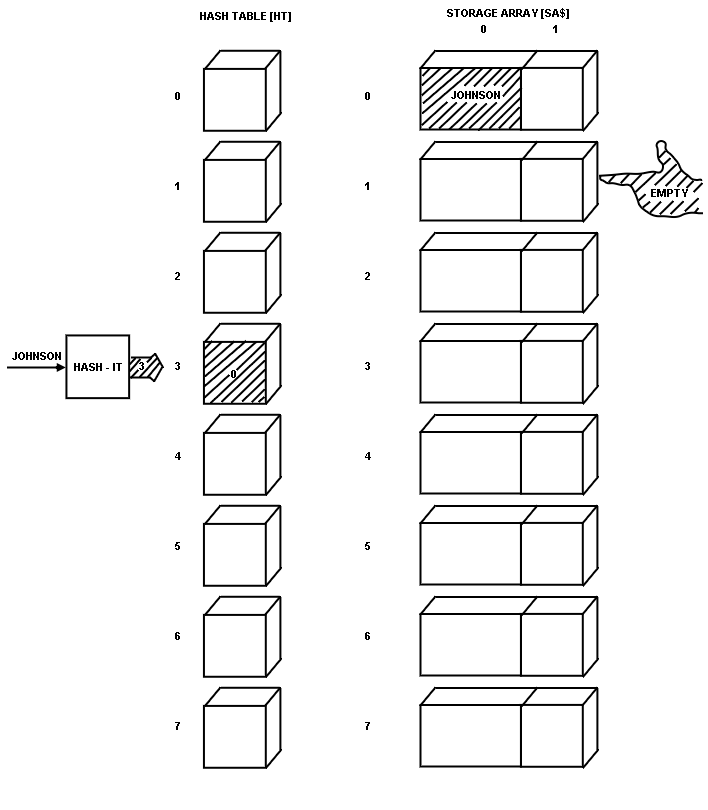
The first name was JOHNSON, which hashed to a numeric value of 3.
The numbered location pointed to by EMPTY was then stored in the HASH TABLE at location 3.
JOHNSON was stored in the STORAGE ARRAY at the location that EMPTY pointed to before being incremented (see
Fig. 5).
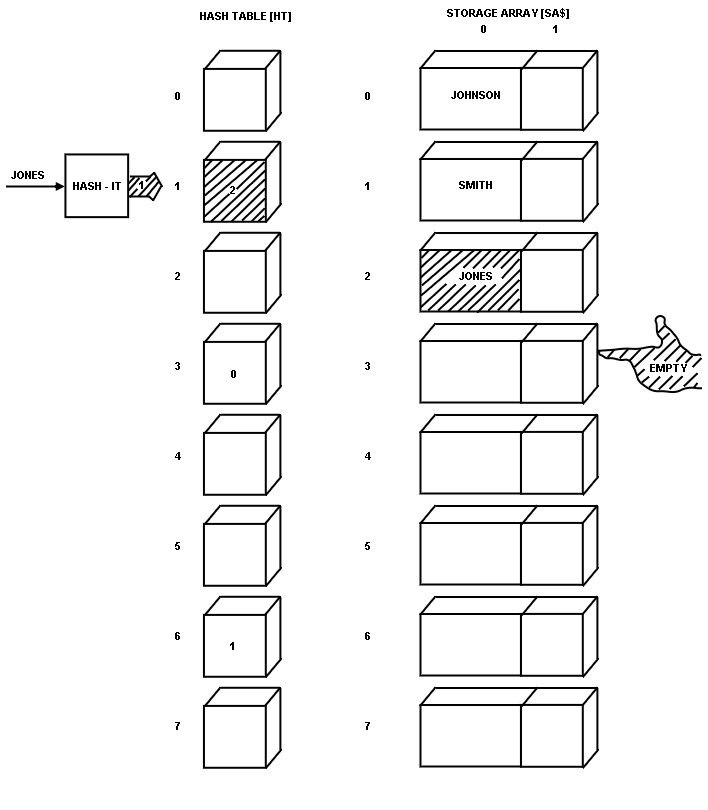
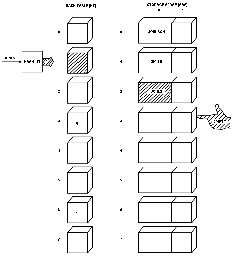
The names SMITH and JONES hashed to values of 6 and 1, respectively.
Figs. 6 and
7 show how they were handled.
Rehash
The demonstration was going well, and my partner was still with me.
All three names had hashed to different numeric values.
So far, so good.
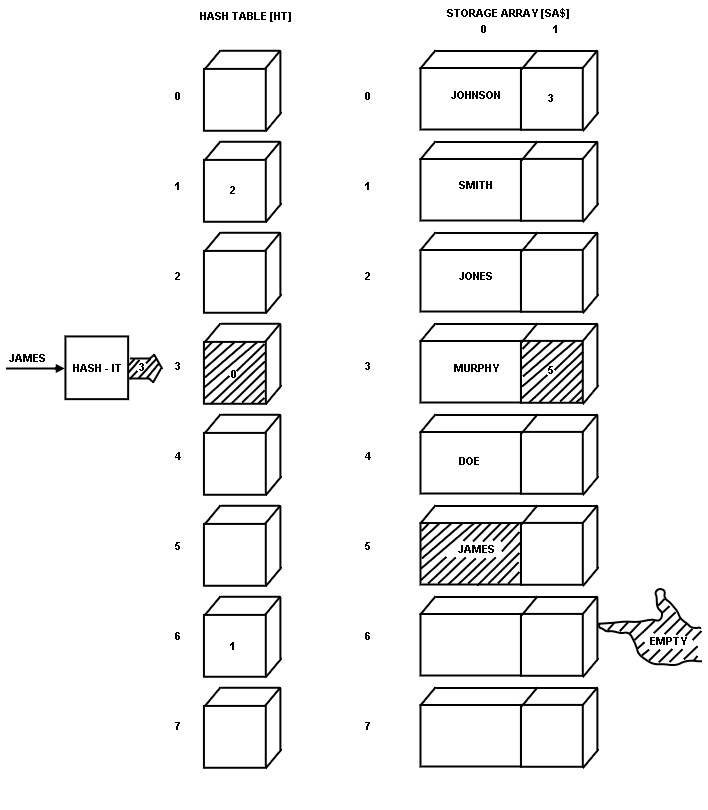
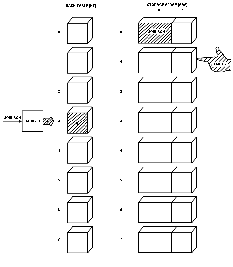
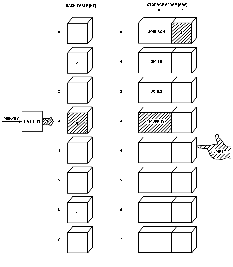
I used the name MURPHY next and found it hashed to a value of 3.
So had JOHNSON!
This was a collision, and I had promised I wouldn't rehash or recalculate the HASH VALUE in order to find an empty element in the HASH TABLE.
So now I had to use that second row of the STORAGE ARRAY.
MURPHY was stored at the next location in the STORAGE ARRAY pointed to by EMPTY.
This location was 3, the sequential element after JONES.
Normally, this value of 3 would be stored in the HASH TABLE at the location pointed to by the HASH VALUE.
However, in this case, there was already a number there, more specifically, the pointer to JOHNSON, I couldn't disrupt this arrangement because I would not be able to find JOHNSON again!
So I stored the value pointed to by EMPTY in the second row of the STORAGE ARRAY element containing JOHNSON.
To find MURPHY later would first require hashing it to a value of 3 (see
Fig. 8).
|

|
Fig. 5.
|
Fig. 6.
|
|
|
Fig. 7.
|
Fig. 8.
|
A look into the HASH TABLE at location 3 would find a pointer value of zero.
The contents of the "zeroth" element of the STORAGE ARRAY would produce JOHNSON.
JOHNSON would not be MURPHY by any means, so a further look would find that the link attached to JOHNSON pointed to the third element of the STORAGE ARRAY.
Further investigation would find that MURPHY resided at this third element of the STORAGE ARRAY, and the search would be done.
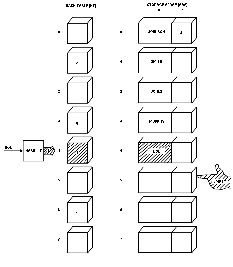
The name DOE was next and gave me no trouble.
It quietly hashed in and was stored as shown in
Fig. 9.
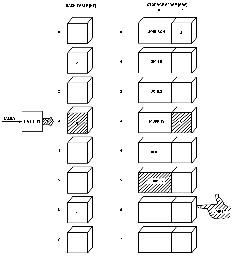
JAMES was not so easy.
It, too, hashed to a value of 3, right in there with JOHNSON and MURPHY.
As handled before, the links were changed, and JAMES joined the group (see
Fig. 10).
|
|
Fig. 9.
|
Fig. 10.
|
The Program
The program listed demonstrates the preceding pictorials and procedures.
Its design is to provide a set of utility procedures to be used in other programs.
The sections called HASH-IT and HASH-IN correspond to the figures above.
I wrote them to simulate the ability to pass and receive parameters between procedures.
Both procedures can be extracted and used in other programs.
The only change to make before HASH-IN can be truly considered general is to delete lines 520 through 524 and lines 527 and 529.
These were written to facilitate the deletion ability of the program.
HASH-IT is general and, as listed, will return a HASH VALUE (HASHV) for a given N$ not equal to a null string ("").
The length of the HASH TABLE (LHT) must be given in line 2120.
HASH-IT was developed by my partner, Mike Smith, to produce hash values from any length keys.
His method first calculates the length of the Key N$.
Then, in lines 2050-2100, the ASCII values of every character in N$ are cumulatively added.
Starting with the first character, every other character of N$ is added and stored in variable A(0).
Simultaneously, every other character, starting with the second character of N$, is added and the sum stored in variable A(1).
This forms two separate numbers that are divided by 256, and their remainders are saved.
The remainder from A(1) is multiplied by 256 and added to the remainder from A(0).
The HASH VALUE is then made equal to this number divided by the variable LHT — the prime number size of the HASH TABLE.
This all takes place in lines 2110-2120.
Uses
The program accepts and stores keys called SUBJECTS.
Along with each SUBJECT, a 256-character miscellaneous field can be stored for later retrieval.
One use of this program is to store names and phone numbers.
The quick retrieval process used makes it a lot faster than your telephone book.
Another idea is to provide an information network affair for clubs or others organizations.
When members want to store subjects with information, they can use the ADD command.
Then when members need to know further information about any subject, a query into the computer may find the desired information.
Quick retrieval and large storage capabilities make this sort of information mill a good application for a microcomputer.
For a large data base, the addition of a data-save procedure can be added.
A disk file can be substituted for the STORAGE ARRAY also.
Conclusion
This program can be used as is, or modified for more complex applications.
The concept of hashing itself is in use with compilers and in DOCUFORM.
Its explanation is intended to add another method of data storage and retrieval to a programmer's bag of tricks.
Im Originallisting wird darauf hingewiesen, dass das Proggramm für einen Apple II Computer geschrieben wurde,
was an Anweisungen wie CALL, PEEK und POKE ersichtlich ist.
Für mehr Informationen siehe die APPLE CALL, PEEK, POKE Liste.
Eingescanned von
Werner Cirsovius
August 2004, Korrektur Juni 2013
© Microcomputing