|
In der „PC AMSTRAD INTERNATIONAL 12'91/1'92" wurde der folgende Artikel abgedruckt.
|
Ein Artikel zum Thema Sortieren.
|
|
Alles in Ordnung?
Sortierverfahren unter der Lupe
Wer einen Computer sein Eigen nennt, wird sicherlich auch bald anfangen, auf diesem eigene Programme zu entwickeln.
Gerade Dateiverarbeitungen erfreuen sich bei Einsteigern sehr großer Beliebtheit.
Aber was tun, wenn die Daten unsortiert in irgendwelchen Feldern stehen?
Sollte man eine Dateiverarbeitung oder irgend etwas ähnliches entwickelt haben, wo viele Daten in ein- oder mehrdimensionalen Feldern verwaltet werden, kann es immer recht nützlich sein, diese in einer ordentlichen Form nach bestimmten Kriterien soriert vorliegen zu haben.
Eine Sortierroutine muß also her.
Die Qual der Wahl
Nun ist es aber so, daß es in der Informatik für jedes Problem mehrere Lösungen gibt.
Da sich schon vor vielen Jahren Wissenschaftler dieser Problematik angenommen haben, fallen diese Lösungen logischerweise immer anders aus.
Die einen — die auf kurze und logische Ergebniss aus waren — entwickelten Routinen mit nur wenigen Programmzeilen.
Die anderen, die mehr auf einen Geschwindigkeitsvorteil als auf ein kurzes Programm aus waren, entwickelten kompliziertere Verfahren wie zum Beispiel Quick-Sort mit seinen rekursiven Aufrufen.
Quick-Sort
Dieses Verfahren wurde von dem amerikanischen Mathematiker C.A.R. Hoare entwickelt.
Hierbei wird ein vorgegebenes Feld so in zwei Teile aufgeteilt, daß in einem Teilfeld die Elemente stehen, die kleiner als ein gewisses "trennendes" Element sind, im anderen Teil die größeren.
Anschließend werden beide Teilfelder nach dem gleichen Muster behandelt, und dies solange, bis man bei einelementigen Mengen angelangt ist.
Nun ist das Feld sortiert.
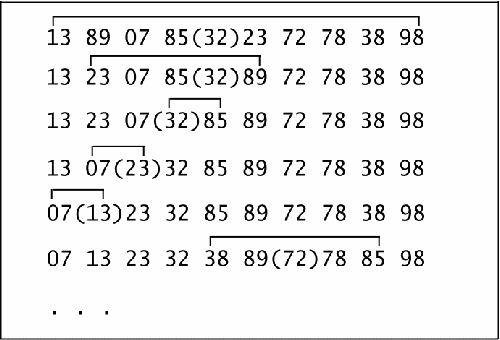
Als Beispiel nehmen wir einmal die Zahlenfolge 98 89 07 85 32 23 72 78 38 13.
Bitte schauen Sie sich für die weitere Erklärung die Abbildung "Das Quicksort-Verfahren" an.
Als trennendes Element wird das jeweils in der Mitte stehende genommen (durch () gekennzeichnet).
Es wird jeweils, zunächst von links beginnend, das erste Element gesucht, das größer als das oder gleich dem Trennelement ist; dann von rechts her das erste Element, welches kleiner oder gleich dem Trennelement ist.
Diese beiden Elemente werden vertauscht.
Select-Sort
Im Gegensatz hierzu basiert das Select-Sort-Verfahren (oder auch Sortieren durch Auswahl genannt) auf einem wesentlich einfacheren Prinzip.
In dem Datenfeld A wird zunächst das kleinste Element herausgesucht und an die vorderste Position gesetzt, das bedeutet, das Element a[1] und das minimale Element tauschen die Plätze (wird im Programm von der Prozedur Switch erledigt).
Unter den verbliebenen Elementen a[2], a[3],...a[n] wird nun wieder das kleinste Element gesucht und mit a[2] getauscht.
Dies geht nun immer so weiter, bis das vorletzte Datenelement erreicht wird.
Heap-Sort
Dieser Algorithmus, den der Amerikaner J. Williams 1964 vorstellte, ist die Weiterentwicklung des Select-Sort-Verfahrens.
Hier wird in einem Feld mit der Länge n das erste Element zur Wurzel eines Baumes erklärt.
Jedes Element dieses Feldes ist zugleich ein Knoten des Binärbaumes, dem wieder ein linker und ein rechter Nachfolger zugeordnet werden kann.
Ein zehn Elemente großes Feld sieht dann zum Beispiel so aus:
1
2 3
4 5 6 7
8 9 10
Auf dieser Struktur basierend kann nun ein Heap (Haufen) aufgebaut werden.
Ein Feld heißt Heap, wenn für alle n Elemente des Feldes folgendes gilt:
Der Wert des i-ten Feldelementes ist größer oder gleich dem Wert des 2xi-ten und des 2xi+1-ten Feldelemnts (i, 2xi, 2xi+1 sind kleiner oder gleich n)
Diese Bedingung erzwingt einen Binärbaum, in dem der 'Vater' größer oder gleich seinem linken und rechten Sohn ist.
| Verfahren | Minuten:Sekunden |
|
| Quick-Sort | 0:31 |
| Heap-Sort | 0:36 |
| Shell-Sort | 0:38 |
| Select-Sort | 1:49 |
| Insert-Sort | 1:51 |
| Bubble-Sort | 2:48 |
|
|
|
Solange benötigen die Sortier-Algorithmen, um tausend Datensätze zu sortieren.
|
Das größte Element eines Heaps befindet sich stets an der ersten Stelle des Feldes.
Ein solches Heap wird auch Maximal-Heap genannt.
Analog zu dieser Form kann ein Minimal-Heap definiert werden.
Für dieses Heap gilt dann die Regel, daß der "Vater" nicht größer sein darf, als sein rechter oder linker "Sohn".
Bei der eigentlichen Sortierung, kann man also in zwei Schritte unterteilen:
- Das Feld wird zu einem Heap transformiert
- Das erste (kleinste oder größere) Element wird mit dem letzten (größten oder kleinsten) Element vertauscht und das Feld um das letzte Feldelement verkürzt.
Werden diese zwei Schritte entsprechend der Anzahl der Felder minus eins mal wiederholt, ist das Feld sortiert.
Eine Lösung dieser Problematik können Sie dem Listing Heap.Inc entnehmen.
Insert-Sort
besser Sortieren durch Einfügen ist eine weitere interessante Art, Daten in die richtige Ordnung zu bringen.
Die Geschwindigkeit ist ungefähr mit der beim Select-Sorting zu vergleichen.
Bei der Entwicklung dieses Verfahrens ging man davon aus, daß ein vorsortiertes Feld vorliegt, in welches ein weiteres Element aufgenommen werden soll.
Das jeweils neu hinzukommende Element wird nun — bei Stelle 1 beginnend — mit den Listenelementen verglichen.
Es wandert nun solange zu größeren Platznummern, bis es auf ein Listenelement stößt, daß größer als es selbst ist.
Damit ist die Einfügestelle gefunden.
Jetzt werden alle größeren Listenelemente um eine Stelle nach rechts geschoben und das Element wird an der gefundenen Stelle eingefügt.
Shell-Sort
Das Shell-Sort-Verfahren (1959, D.L. Shell) ist wiederum eine Weiterentwicklung eines bereits vorhandenen Algorithmus.
Das Sortieren durch Einfügen wird hier noch effizienter realisiert, da hier Verschiebeoperationen über größere Entfernungen hinweg durchgeführt werden.
Im ersten Durchlauf wird das Datenfeld in zwei Teilfolgen mit der Länge des Gesamtfeldes Div 2 sortiert.
Logischerweise beträgt nun auch die Entfernung der Elemente der Teilfolgen untereinander genau die Länge des Gesamtfeldes Div 2.
Nun werden alle Teilfolgen nacheinander sortiert.
Im zweiten Durchlauf wird die Entfernung zwischen den Elementen einer Teilfolge halbiert;
die Länge der Teilfolgen verdoppelt sich dann automatisch.
Hiernach werden diese neuen Teilfolgen nochmals sortiert.
Auch in den nächsten Durchläufen wird dieses Verfahren wiederholt, und im letzen Durchgang beträgt die Entfernung zwischen den Elementen einer Folge eins, was bedeutet, daß nur eine Teilfolge vorliegt, deren Länge der Feldlänge entspricht.
Im Vergleich zum Insert-Sort-Verfahren erzielt Shell-Sort wirklich ein enorm gutes Ergebnis.
Bubble-Sort
Ein einfaches, jedoch nicht gerade schnelles Verfahren stellt die Austauschroutine da.
Hierbei wandern die Werte der zwei Schleifenvariablen (i,j) jeweils von zwei bis zur Datensatzgröße (i) und von der Datensatzgröße bis i (j).
Die zweite For-Schleife übernimmt hier das Durchlaufen des Restfeldes mit den impliziten Vergleichen und den entsprechenden Verschiebungen.
Die äußere For-Schleife übernimmt das kontinuierliche Verkürzen des Restfeldes.
Beispielprogramme
Die als Listing ausgedruckten Beispielprogramme stellen die einzelnen Sortierverfahren noch einmal als Pascal-Listing da.
Das Hauptprogramm SORT.PAS bindet die einzelnen Programmteile ein und demonstriert die einzelnen Sortierverfahren.
Es ist grundsätzlich auch dafür zu gebrauchen, um nach dem Eingeben erst einmal die einzelnen Sortierverfahren auf richtiges Eingeben zu überprüfen.
Nach dem Start von SORT.PAS wird jeweils das LeerArray mit durcheindergewürfelten Integerwerten gefüllt.
Die Inhalte des unsortierten Arrays werden nun auf dem Bildschirm ausgegeben und im Speicher mit dem jeweiligen Verfahren sortiert.
Nun findet eine Ausgabe des sortierten Arrays statt, und es wird mit dem nächsten Sortierverfahren weitergemacht
Um eine Kompatibilität des Programms auch mit anderen CP/M-Maschinen zu gewährleisten, wurde der Geschwindigkeitstest unter CP/M ausgeführt.
Hierzu wurde ein Programm geschrieben, daß so aussah:
Program Test;
Type StudentArray = Array[1..1000] Of Integer;
Student = Integer;
Var TestArray: StudentArray;
Loop: Integer;
{$IBubble.Inc}
Procedure Fill;
Begin
For Loop: =1 to 1000 Do
TestArray[Loop]:=Random(1000)+1;
End;
Begin { Test }
Fill;
BubbleSort(TestArray,1000);
End. {Test}
Die hier fett markierten Punkte sollten nun je nach dem gewünschten Sortierverfahren entsprechend abgeändert werden.
Der eigentliche Test kann nun direkt unter CP/M durch Eingabe von
DATE!TEST!DATE
gestartet werden.
Voraussetzung hierfür ist jedoch, daß sich das CP/M-Dienstprogramm DATE.COM auf dem aktuellen Laufwerk befindet.
Subtrahiert man nun die erste angegebene Zeit von der zweiten, kommt man auf die benötige Zeit für das Sortieren.
Hierbei werden zwar auch Diskettenzugriffe mit einbezogen, sie sind jedoch bei jedem Verfahren gleich und fallen somit nicht sonderlich ins Gewicht.
Außerdem bietet sich auch die Möglichkeit an, wenn man im Besitz einer RAM-Disk ist, alle benötigten Dateien auf diese zu kopieren.
Ralf Schößler
Empfohlene Literatur:
- Pascal, Samuel L. Marateck, John Wiley & Sons, ISBN 0-471-60546-8
- Pascal at Work and Play, Richard S. Forsyth, Capman and Hall, ISBN 0-412-23380-0
- Das Arbeitsbuch zu Turbo-Pascal, Karl Udo Bromm, Sybex, ISBN 3-88745-629-7
- Programmieren mit Pascal, Rüdeger Baumann, Vogel Verlag, ISBN 3-8023-0667-8
- Programmieren mit Turbo-Pascal 3.0, Winfried Kassera, Markt & Technik, ISBN 3-89090-159-X
|

|
|
Das Shell-Sort-Verfahren
|
|
|
| [SORT.PAS] |
|
|
| [BUBBLE.INC] |
|
|
| [SELECT.INC] |
|
|
| [INSERT.INC] |
|
|
| [HEAP.INC] |
|
|
| [QUICK.INC] |
|
|
| [SHELL.INC] |
Eingescanned von
Werner Cirsovius
August 2004
© DMV-Verlag