Im Magazin „ Dr. Dobb's Journal of Computer & Orthodontia" wurde in der Nummer 30 (Jahr unbekannt) der folgende Artikel abgedruckt.
Ich habe den Artikel hier übersetzt
|
Dieser sehr gute Artikel befasst sich auf praktische Weise mit einem Sortierproblem, wie man es beim Arbeiten mit Symbolen findet.
|
|
Binary Tree Manipulation on the 8080
BY MIKE GABRIELSON
Box 2692
Stanford, Calif. 94305
|
Imagine that we are writing a compiler.
How should the symbol table be organized?
One possibility is to use a binary tree.
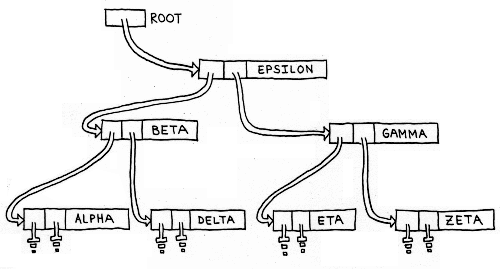
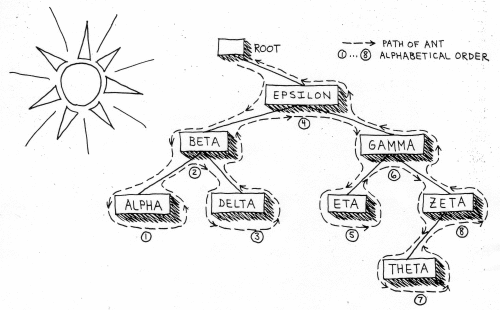
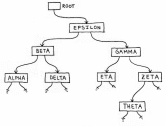
Figure 1 illustrates a binary tree that contains seven symbols (strings representing variable names).
Figure 1. A Binary Tree
|
|
Each symbol is contained in a
node along with two
pointers.
The pointers are used to link together the nodes of the tree.
A special pointer called the
root points to the topmost node of the tree.
(Computer trees grow upside down.)
Grounded pointers on the bottommost nodes have nothing to point to.
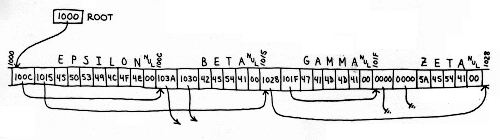
On the 8080 and similar computers, we can let each pointer be a 16 bit address, and each symbol can be an ASCII string.
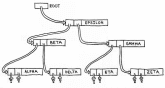
Figure 2 shows a portion of our tree as it might actually be stored in an arbitrary region of memory.
Figure 2. The Tree Stored in Memory
|
|
By convention, we will set grounded pointers to a zero value, and delimit each string with the NUL character.
An actual symbol table for a compiler would include some extra bytes in each node for flags, values, and other information about each symbol, but we'll ignore that to simplify the examples.
The symbols in our tree are arranged in a special way:
if we pick any node, we find that the left pointer (if not grounded) points to a subtree containing symbols all alphabetically less than (preceding) the symbol in the node.
Similarly, the right pointer points to a subtree containing symbols all alphabetically greater than (following) the symbol in the node.
Maintaining the tree in this ordered manner allows us to design very simple but effective algorithms to manipulate the data in the tree.
For example, suppose our compileer needs to look for a symbol in the tree.
How should the tree be searched?
Starting with the first node (pointed to by the root), we compare the node's symbol to the symbol we desire.
If there's a match, we're done.
If our symbol is less than the node's symbol, we follow the node's left pointer and repeat the test with that node.
If our symbol is greater, we pick the right subtree, and so on down the branches until we find a match or until we reach a grounded pointer, which indicates the symbol is nowhere in the tree.
The sample subroutine called SEARCH will search a binary tree like ours using this algorithm.
| Subroutine called SEARCH: |
|---|
|
|
| [Listing] |
How do we grow a tree in the first place?
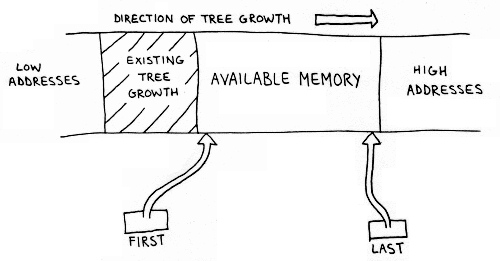
One necessary ingredient to grow a tree is memory.
Let's assume we have access to two new pointers.
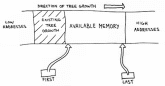
One pointer is called FIRST and is the address of the first byte of a contiguous chunk of memory available for the tree.
The last available byte in the chunk is pointed to by LAST.
This arrangement is illustrated in Figure 3.
Figure 3. Memory Allocation
|
|
Each time our tree needs a byte to grow, it can grab the byte pointed to by FIRST, and then increment FIRST.
Memory is exhausted when FIRST passes LAST.
Now we can modify our search so that when a symbol is not found in the tree, a new node is automatically grown for it.
The next listing is a subroutine called LOOKUP which appends new symbols to the tree as necessary.
(To simplify the code, this version of LOOKUP does not check if FIRST passes LAST, indicating memory overflow.)
An example of a call to LOOKUP is
LXI B,STRING ;get address of string
LXI H,ROOT ;get address of ROOT
MOV D,M ;get contents of ROOT
INX H
MOV E,M
DCX H ;restore address of ROOT
XCHG ;adjust registers for LOOKUP
CALL LOOKUP
The calling sequence can be simplified if the contents of the 16-bit root and node pointers are maintained in standard Intel byte-reversed format, instead of unreversed as the code currently requires.
Changing the code so that all pointers are byte-reversed is an easy exercise left to the reader.
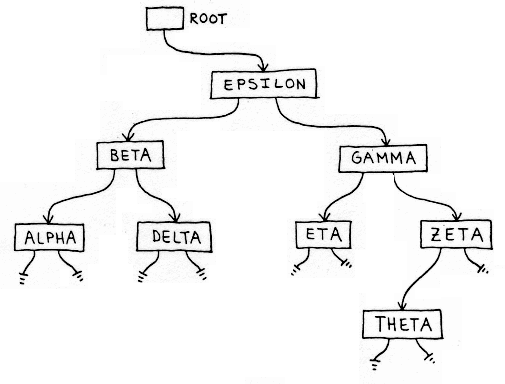
Figure 4 shows how the tree has grown after a LOOKUP of the symbol THETA.
Figure 4. New Growth
|
|
| Subroutine called LOOKUP: |
|---|
|
|
| [Listing] |
A nice feature for our compiler would be the capability of listing the symbol table in alphabetical order.
How can we list our tree?
Because of the way the tree is ordered, one elegant algorithm we can use works as follows:
before listing any node, first list the node (subtree, if any) pointed to on the left, then list the original node, then list the node (subtree) pointed to on the right.
Start with the node pointed to by the root, but always try to first visit the left subtree at each node.
This is a recursive algorithm that is easy to implement on machines with a stack like the 8080.
The final sample program is a recursive routine called PUTREE that will dump our tree using this algorithm.
An example of a call ta PUTREE is
LHLD ROOT ;get contents of ROOT
MOV A,H ;swap H and L
MOV H,L ;to be consistent with
MOV L,A ;rest of tree
ORA H ;is root grounded?
CNZ PUTREE ;no, output tree
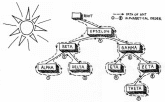
A way to visualize what's happening is to imagine an ant visiting each node by crawling around the edges of the tree (see Figure 5).
Figure 5. Tree Traversal
|
|
If the sun is shining from the upper left, and the ant shouts out each symbol the first time it crawls along a shaded side of the symbol's node, then the symbols will be shouted out in alphabetical order.
| Subroutine called PUTREE: |
|---|
|
|
| [Listing] |
Eingescanned von
Werner Cirsovius
August 2002
© Dr. Dobb's Journal